In this series on Original Research, I will be sharing about my findings from some of the mini-projects that I have carried out on my own.
Fast-and-frugal trees (FFTs) are a specific type of classification decision tree with sequentially ordered cues, where every cue has two branches and one branch is an exit point (Martignon et al., 2003). The final cue in the sequence will have two exit points to ensure that a decision is always made. The whole point of using FFTs is to allow decisions to be optimised with as few cues as possible, especially when decision making is time-constrained and needs to be immediate. The figure below is a classic example of a ischemic heart disease decision tree trialed by Green & Mehr (1997).
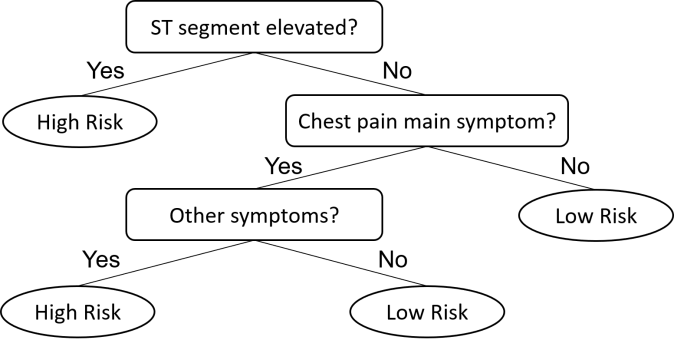
Green & Mehr (1997) FFT for categorising patients as having a high or low risk of ischemic heart disease.
Green & Mehr (1997) trialed the tree to help physicians determine the risk level of patients, to ensure that patients most likely suffering from acute ischemic heart disease get medical attention immediately, and that patients of low risk do not consume intensive care resources unnecessarily. They discovered that 3 cues were all it took to make such a decision, based on the historical records of patients suffering from acute ischemic heart disease. As the decision concerns a life-and-death situation, the decision tree is naturally biased towards avoiding misses, where high risk patients are immediately identified just based on the first cue. This was probably done at the cost of having more false alarms.
The above description of FFTs sounds great, but with the availability of machine learning, some have questioned the reliability of FFTs compared to machine learning classification trees. To address this doubt, Martignon et al. (2008) have conducted studies to show that the predictive accuracy of FFTs is actually comparable to decision trees generated by machine learning. As the main proponent of FFTs, Gerd Gigerenzer’s ABC group of the Max Planck Institute argue that FFTs are more cognitively plausible to internalise as compared to complex machine-learning algorithms. Nonetheless, there seems to be a lack of behavioural studies in the literature to support such a claim, prompting me to conduct a study to test this claim.
How Are FFTs Constructed?
Before sharing about my study, let me first explain how FFTs are constructed. Using the steps laid out by Martignon et al. (2003), I will show how the Green & Mehr (1997) FFT is being constructed.
- Collect historical data of medical cues used to test patients suspected with acute ischemic heart disease, together with the actual outcomes of whether they really suffered from it.
- Tabulate the Hits, Misses, False Alarms and Correct Rejections of each cue, as though they were used individually.
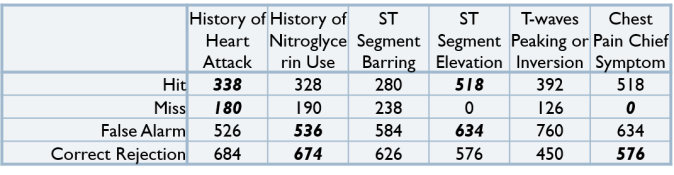
- Calculate the Hit Rate, Correct Rejection Rate, True Discovery Rate and True Omission Rate of each cue. (To learn more about calculating rates in a confusion matrix, please take a look at my previous blog post on Confusion Matrices.)
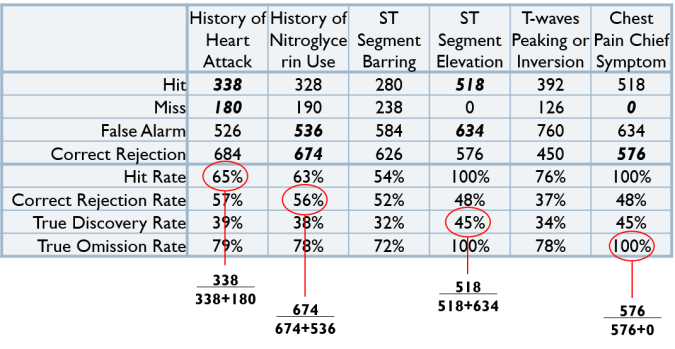
- Order the cues either based on Hit Rate and Correct Rejection Rate from highest to lowest value, or based on True Discovery Rate and True Omission Rate from highest to lowest value. Cues can be ordered leniently to avoid misses, or conservatively to avoid false alarms.
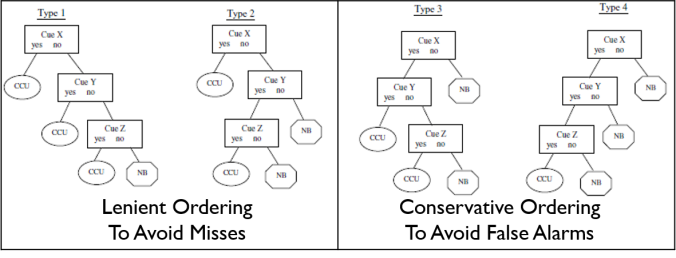
- Compute the decision outcomes from these various ordering, and calculate the Hits, Misses, False Alarms and Correct Rejections to determine the performance of the FFTs to decide on the ordering that favours the situation.
With a better understanding of how FFTs are constructed, we can now talk about how my study was conducted to find out if FFTs are truly cognitively easy to use, and whether people are really unable to use slightly more complex machine learning trees.
Context of Study
Using a car evaluation dataset from UC Irvine Machine Learning Repository, participants of the study were told to imagine themselves as a car dealer who wants to select cars that will be considered acceptable by potential customers, as well as avoid cars that will be considered unacceptable. They had to evaluate whether a car was acceptable or not based on 6 attributes (that came from the dataset), with the help of a decision tree that was given to them.
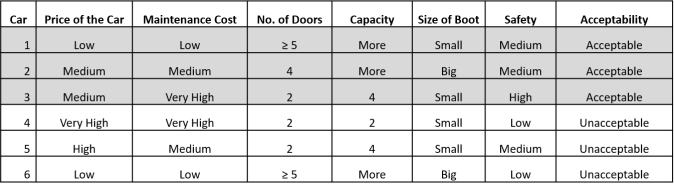
Examples of cars that were considered acceptable/unacceptable, together with their attributes.
Two decision trees were generated from the dataset – one C4.5 machine learning tree (using Weka) and one FFT (using the method described above). Participants were randomly assigned to use only one of the two decision trees.

C4.5 machine learning tree with 3 cues.
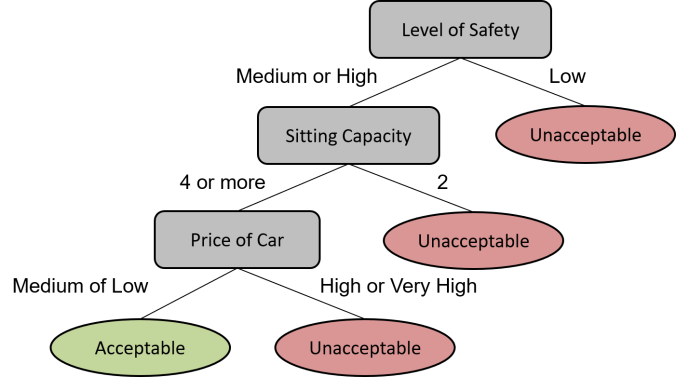
Conservatively ordered FFT with 3 cues.
While there were a total of 6 attributes in the dataset, constructing the FFT with 3 cues was found to be optimal and adding another cue did not improve the evaluation accuracy. The cues were ordered in a conservative fashion where a car is considered acceptable only if all 3 cues were satisfied. This was based on the rationale that it would be more costly for a car dealer to choose an unacceptable car by mistake, compared to missing out on acceptable cars.
Since the FFT only used 3 cues, the C4.5 machine learning tree had to be constructed with the same 3 cues for a fair comparison, even though a C4.5 machine learning tree with 6 cues had a better evaluation accuracy. While the C4.5 tree with 3 cues looks relatively simple, a C4.5 tree with 6 cues was a lot more complex. The table below shows how the decision trees compare with each other in terms of evaluation accuracy.
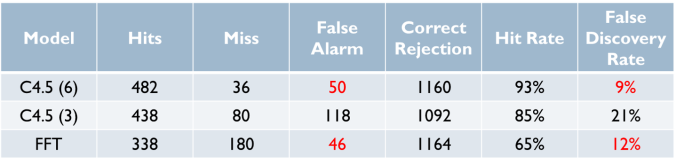
Comparison of evaluation accuracy.
As we can see, the hit rates of the C4.5 machine learning trees were generally better than the FFT. However, as the FFT was ordered conservatively, the number of false alarms could be greatly reduced, resulting in a False Discovery Rate that is even less than the C4.5 (3). Nonetheless, it is important to remember that this just describes the performance of the trees, and not the performance of the human participants who will be using them. For the purpose of the study, only cars that were correctly categorised by both the C4.5 (3) and FFT were selected.
Study Design
The design of the study was very simple. The 30 recruited participants were first asked to evaluate 20 cars without a decision tree, followed by 1 minute of memorisation of the tree they were randomly assigned to, before completing a new set of 20 cars. As only cars that were correctly categorised by both the C4.5 (3) and FFT were selected for the 2 sets of 20 cars, any mistake made would be purely human error and not due to the tree’s performance. The results of such a study design will then hopefully provide insights on whether FFTs are truly easier to use than comparable machine learning trees.
Besides recording the scores and completion timings of the participants, self-reports such as confidence and ease of task were also collected. Participants were also requested to verbalise their thought process when completing the task with the decision tree, and asked to sketch their memory of the decision tree after they have completed the task.
Results
Unsurprisingly, scores and completion timings of the participants were statistically better when they had a decision tree to use. Self-reported confidence and ease of task also increased statistically with the use of decision trees. While most of these measures did not differ statistically between the C4.5 group and FFT group, the FFT group generally had higher means. Nonetheless, there were a couple of measures that had significant differences between the two groups (see below).
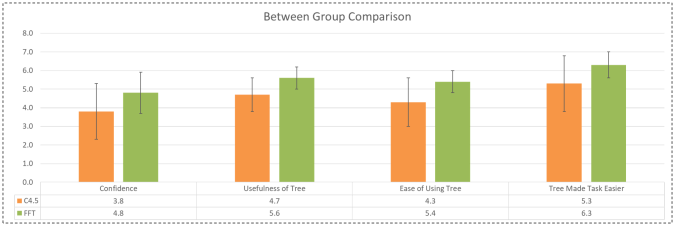
Comparison of self-reports between the C4.5 group and FFT group.
Participants who used the FFT were confident in completing the task, found the tree to be useful, found the tree easy to use, and felt that the tree made the task easier, statistically more so than participants who used the C4.5 tree. While not tested for significance using Chi-Square analysis, there were also more participants in the FFT group scoring full marks when using a decision tree. On the contrary, there were more participants in the C4.5 group who took more time completing the task with a tree than without, reported using the tree as making the task more difficult, and did not think that they scored better having used a decision tree. All of these point towards the C4.5 tree being more difficult to use, as it may be more difficult to remember.
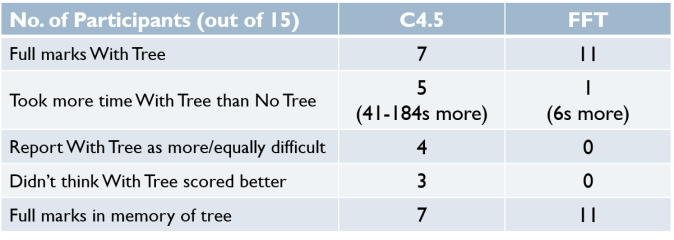
Other noteworthy findings.
The results of the memory sketch were quite fascinating. Most participants in the FFT group were able to reproduce the tree in full, while participants in the C4.5 group who were able to recall their tree often did so in a heuristic fashion. In fact, while participants in the C4.5 group verbalised their thought process during the task, it seemed as though they were making the evaluations in the form of an elimination. They would first pick out the cars that were considered acceptable, and treat everything else as unacceptable. Interestingly, this was pretty similar to how the FFT was structured.
Conclusion
It is certainly premature to conclude that FFTs are cognitively easy to use just based on the results of this mini-study, but most of the observations seem to suggest that they may be easier to remember than a machine learning tree that has more branches. In fact, from the way participants used the C4.5 tree, it appears that an FFT may be how people intuitively make decisions when using multiple cues. A likely reason for this is because while an FFT has two branches at every node, the two branches are often opposites of each other, allowing the knowledge of one branch to inform about the other. This significantly cuts down the number of things required for memory, and allows for much quicker processing, especially through an elimination approach.
Despite the promising results, my personal takeaway from conducting this study is that even in time-constrained decision making, practitioners may actually be better off using a computerised decision tool with better performance. However, if a computerised decision tool is unavailable, FFTs can still be very useful, intuitive and accurate enough, especially for situations where decisions have to be made instantaneously.
This research has been presented at the 39th Annual Meeting of the Cognitive Science Society in 2017, in London, United Kingdom.
References:
-
Green, L., & Mehr, D. R. (1997). What alters physicians’ decisions to admit to the coronary care unit?. Journal of Family Practice, 45(3), 219-226.
-
Martignon, L., Katsikopoulos, K. V., & Woike, J. K. (2008). Categorization with limited resources: A family of simple heuristics. Journal of Mathematical Psychology, 52(6), 352-361.
- Martignon, L., Vitouch, O., Takezawa, M., & Forster, M. R. (2003). Naive and yet enlightened: From natural frequencies to fast and frugal decision trees. Thinking: Psychological perspective on reasoning, judgment, and decision making, 189-211.

Nice study—I think that there have not been systematic evaluations of whether fast and frugal trees are indeed easier to apply, memorize etc. Developing this into a full-fledged research program would be valuable across disciplines. A few constructive comments:
1. The C4.5 tree is also a fast and frugal tree, if the definition of such a tree is naturally extended from binary to categorical cues (general definition: at least one exit per cue query). In this sense, your study pits binary vs categorical cues and their consequences for the complexity of a fast and frugal tree. Does your data support such an interpretation?
2. Did your participants comment on the accuracy (perceived or real) of the two trees? Did they seem to believe in a simplicity-accuracy trade off? Did they mention that they might use a machine learning tree so as to appear more “accountable”, “serious”, etc?
3. Are you aware of the work of Şimşek (Uni of Bath) and Buckmann (Bank of England) on how often CART-induced trees end up being fast and frugal? I think it was published in ICML.
LikeLiked by 1 person
Hi Dr Katsikopoulos! It’s an honour to have someone associated to the Max Planck Institute notice and comment on my blog. 🙂 I am actually friends with Shenghua and Jolene, and it was Shenghua who introduced me to FFTs back when I was still an undergraduate almost a decade ago.
I agree that understanding how FFTs are applied would be valuable, and it seems most natural to me that people who want to promote the usefulness of FFTs should be studying about this. I tried sharing about this during CogSci conference at London in 2017, but the interest was lukewarm.
1. Thanks so much for your comments. I really appreciate the thoughtfulness. But I’m not sure if I fully understand your first question. My understanding of FFTs is that they are typically binary, and while I understand that while we may think of them as categorical if we extend the definition to “at least one exit per cue query”, my data does show that the participants handled the two trees quite differently. Then again, I must caveat that the sample size is quite small, and I wouldn’t make any real conclusions from the data.
2. Very interesting question. I suppose this question comes from the intuition that a simple tree can’t be that accurate, and I think that hypothesis is worth testing. Unfortunately, in the case of this study, I do not think that the participants are too concerned about whether the FFT is indeed accurate in determining whether a car was acceptable or not, since the cases chosen were all correct for both the C4.5 and FFT, and the participants were only focused in getting their answers correct. Besides, the participants were only exposed to one of the trees, so they didn’t really have anything else to compare what they received against. But if allowed to compare the two trees side-by-side (without knowledge of the trees’ actual performance), it would be interesting to see if the participants would think that the more complex tree is more accurate.
3. I am unaware of this work unfortuntely, but it sounds quite relevant to what is happening here. I’d be happy if you could point me to it.
I am actually no longer a student or in academia, so I’m not exactly free to pursue this as a full research program. But if you or anyone you know is interested in building on this mini-study, I’d be more than happy to help in any capacity that I can, although likely through a long-distance working relationship. 🙂
LikeLike
Pingback: Get Technical: Decision Trees > better.sg
Pingback: Nudging for Good: How to Improve Recycling Using Behavioural Insights | The Curious Learner